- Published on
Linear Algebra 101 for AI/ML – Part 2
- Authors

- Name
- Backprop
- @trybackprop
Intro
In Part 1 of this Linear Algebra 101 for AI/ML Series, we learned about the fundamental building blocks of linear algebra: vectors and matrices. We learned how element-wise operations apply to the vector/matrix's individual elements independently, and then we played around with these mathematical building blocks using an open source ML framework called PyTorch, widely used in academia and industry.
In this article, Part 2 of the series, we will build on that foundational knowledge. First, we will cover an operation that applies to the vector/matrix's individual elements as a whole: the dot product. This operation belongs to a class of operations that do not view the individual elements independently. Then we will visualize the dot product operation to build intuition, and finally, we will learn about embeddings, which are special types of vectors that represent concepts, objects, and ideas. Embeddings are used throughout modern AI and have applications in large language models, image generation models, and recommendation systems. In the article, you will find questions, a quiz, and two interactive playgrounds (the Interactive Dot Product Playground and the Interactive Embedding Explorer are best viewed on laptop/desktop) that were designed to help you understand the concepts.
In Part 3 of the series, we will use all the fundamental linear algebra we will have learned in Part 1 and Part 2 to build an image search engine. Below is a preview of the image search engine, which returns images similar to the user's input image.

Without further ado, let's get started!
Dot Product
We will approach the dot product from two perspectives: an algorithmic perspective and a visual one.
Algorithmic Perspective
Below are two vectors, and .
The notation for the dot product is simply a dot between two vectors: . The algorithm for calculating a dot product is simply to sum the products of corresponding pairs between two vectors. Let's break down what that means. First, let's calculate the products:
Next, we sum the products:
Thus, . Let's see how to calculate the dot product with PyTorch.
>>> a = torch.tensor([1.0, 2.0, 4.0, 8.0])
>>> b = torch.tensor([1.0, 0.5, 0.25, 0.125])
>>> torch.dot(a, b)
tensor(4.)
To put it another way, to calculate the dot product, first we use the element-wise multiply operation, and then we sum up the products. Just for fun, let's implement torch.dot with native Python:
>>> sum([a[i] * b[i] for i in range(len(a))]) # Python implementation of dot product
tensor(4.)
Visual Perspective
At this point, you're probably wondering: what does the dot product mean? Is there any meaning behind element-wise multiplying two vectors and then summing up the products? To aid our understanding of the dot product visually, let's introduce another way to calculate the dot product. This second equation for calculating the dot product is called the cosine formula for the dot product.
(We won't cover why these two values are equivalent, but the proof can be found here.)
Now that we are familiar with the notation, let's revisit the cosine formula for the dot product:
The reason why we introduced this new cosine formula is it allows us to interpret the dot product geometrically.
Interactive Dot Product Playground
Before we dive into the explanation of the cosine formula for the dot product, let's first play around with an interactive playground that allows you to drag the arrowhead of the vectors around in a 2D number plane (only works on laptop/desktop!). Go ahead and try it out. See how the dot product between vector 1 and vector 2 changes (see the dynamic value of the dot product in the panel). Dragging the arrowheads around allows you to change the angle between the vectors and their lengths. As the cosine formula states, both angle and length (aka norm) have an impact on the dot product.
Vector 1:
(-3.00, 3.00)
Norm 1:
4.24
Vector 2:
(3.00, 2.00)
Norm 2:
3.61
Dot Product:
-3.00
cos(θ):
-0.1961
Tip: Click and drag the arrowheads to move the vectors on laptop/desktop
Have you played around with the interactive playground? If so, now it's time to understand the dot product.
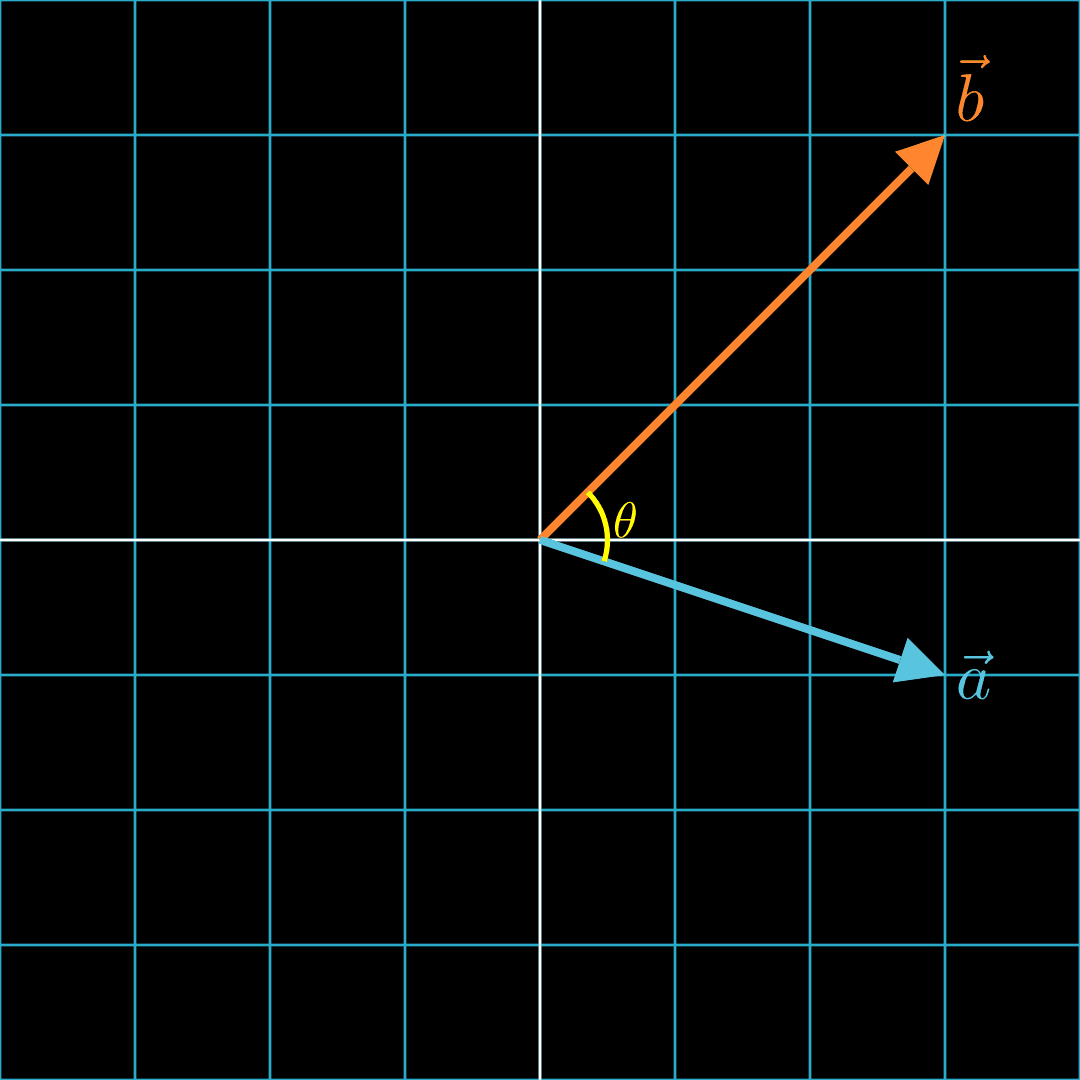
Here, we see two vectors and with an angle of between them.
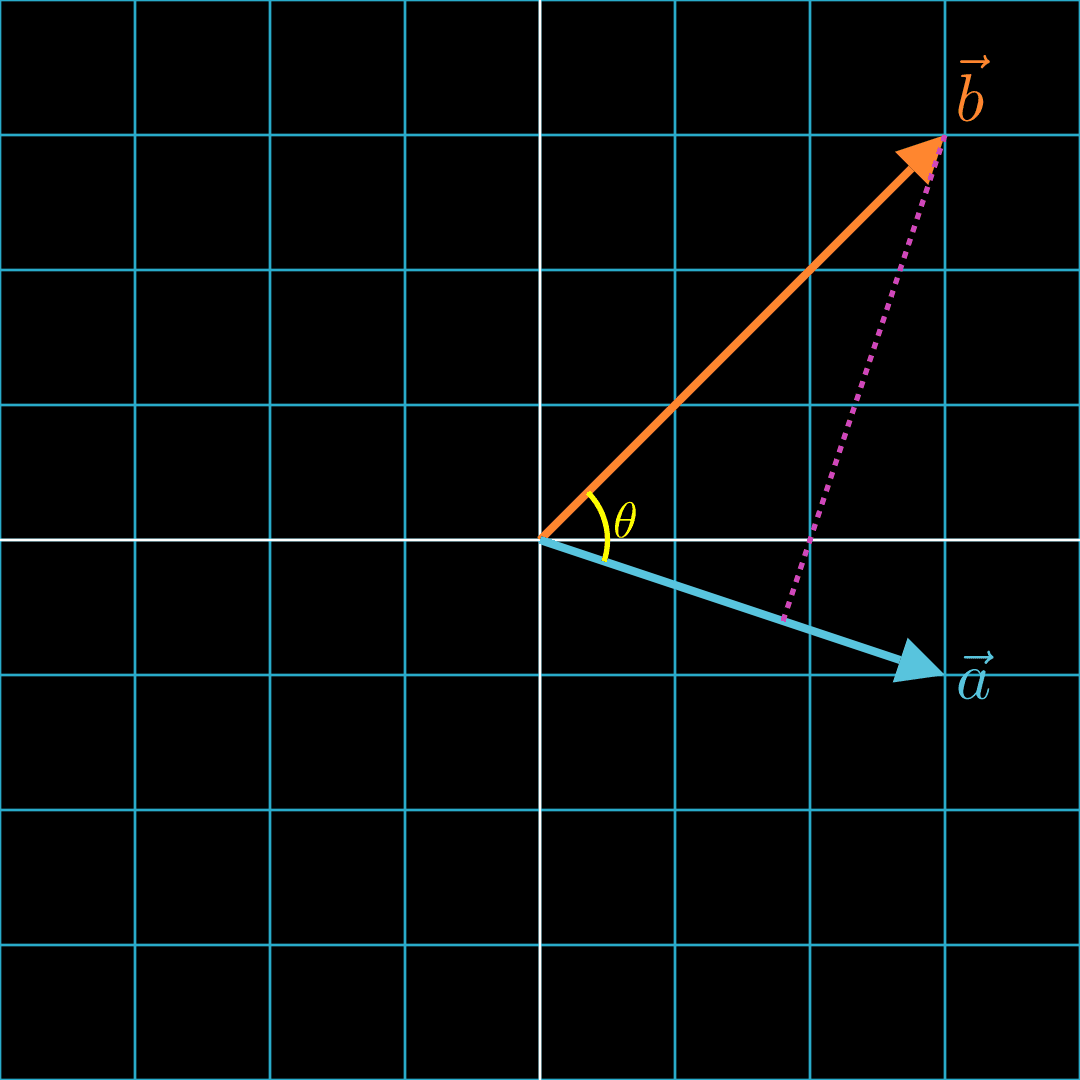
Let's draw a dotted line from the tip of to such that the dotted line is at angle to .
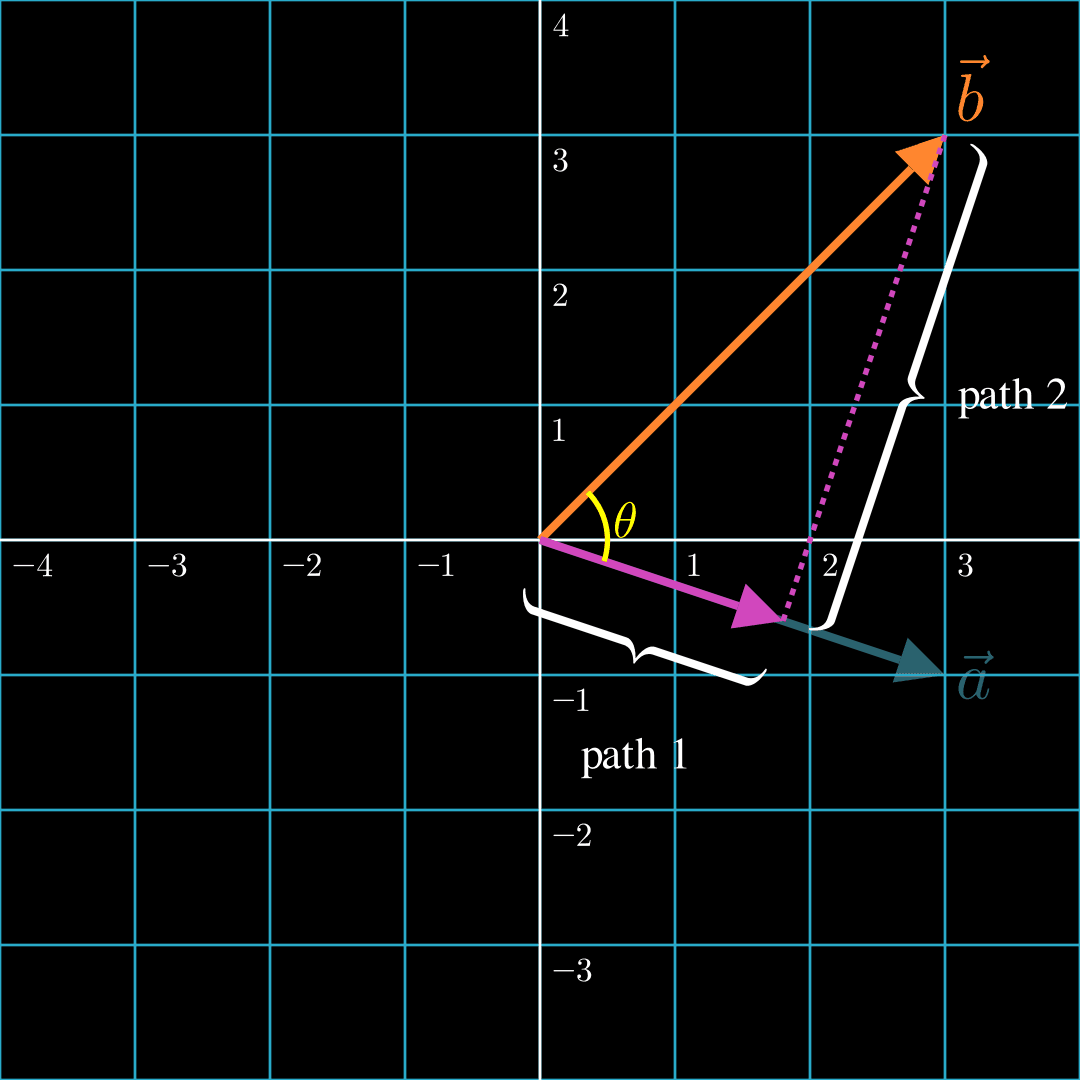
Imagine two forces. The first force moves an object from the origin, , along path 1. The second force then takes over and moves the object along path 2. The object would end up at . Notice that the force that pushes the object along path 1 is in the same direction as . In other words, it's aligned with . This component is called the projection of onto .
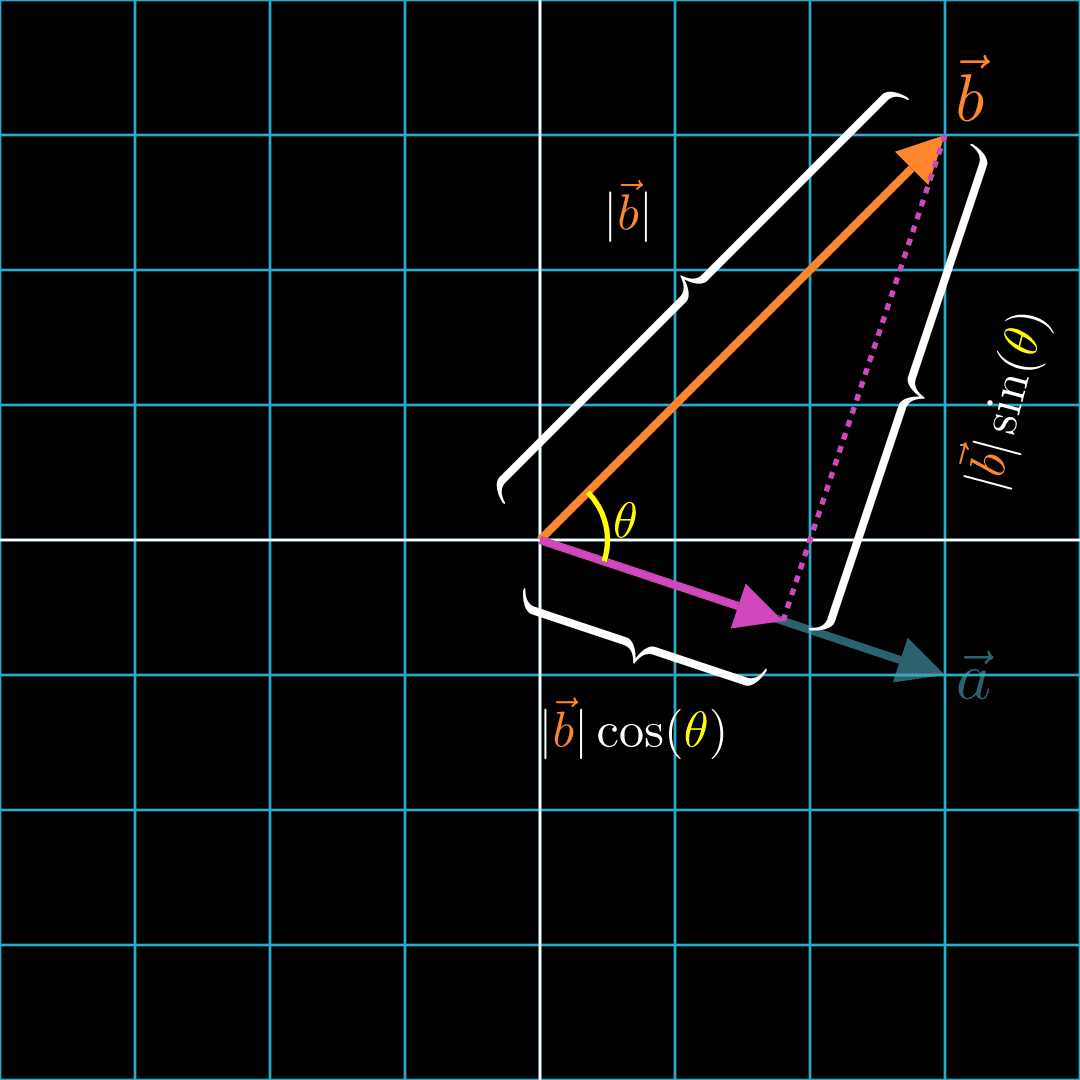
Since path 1, path 2, and make a right triangle, we can calculate the lengths of the paths with trigonometry. We see that the projection of onto has a length of .
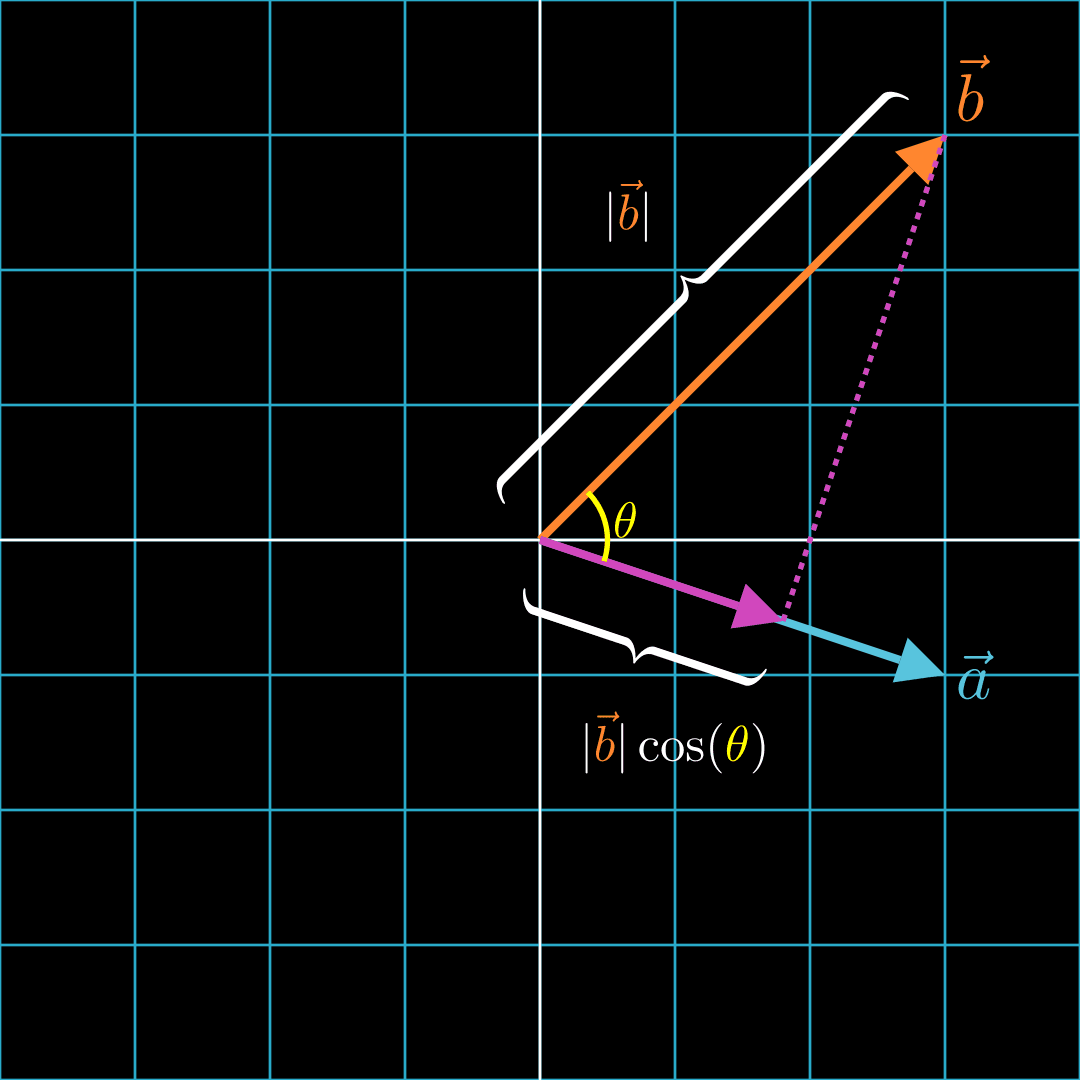
Now we see that multiplying and is essentially the same as multiplying the length of and the length of the component of along the direction of . That means, the more and are aligned and pointing in the same direction, the higher the dot product. The less they are aligned, the smaller the dot product. Let's take a look at some cases below.
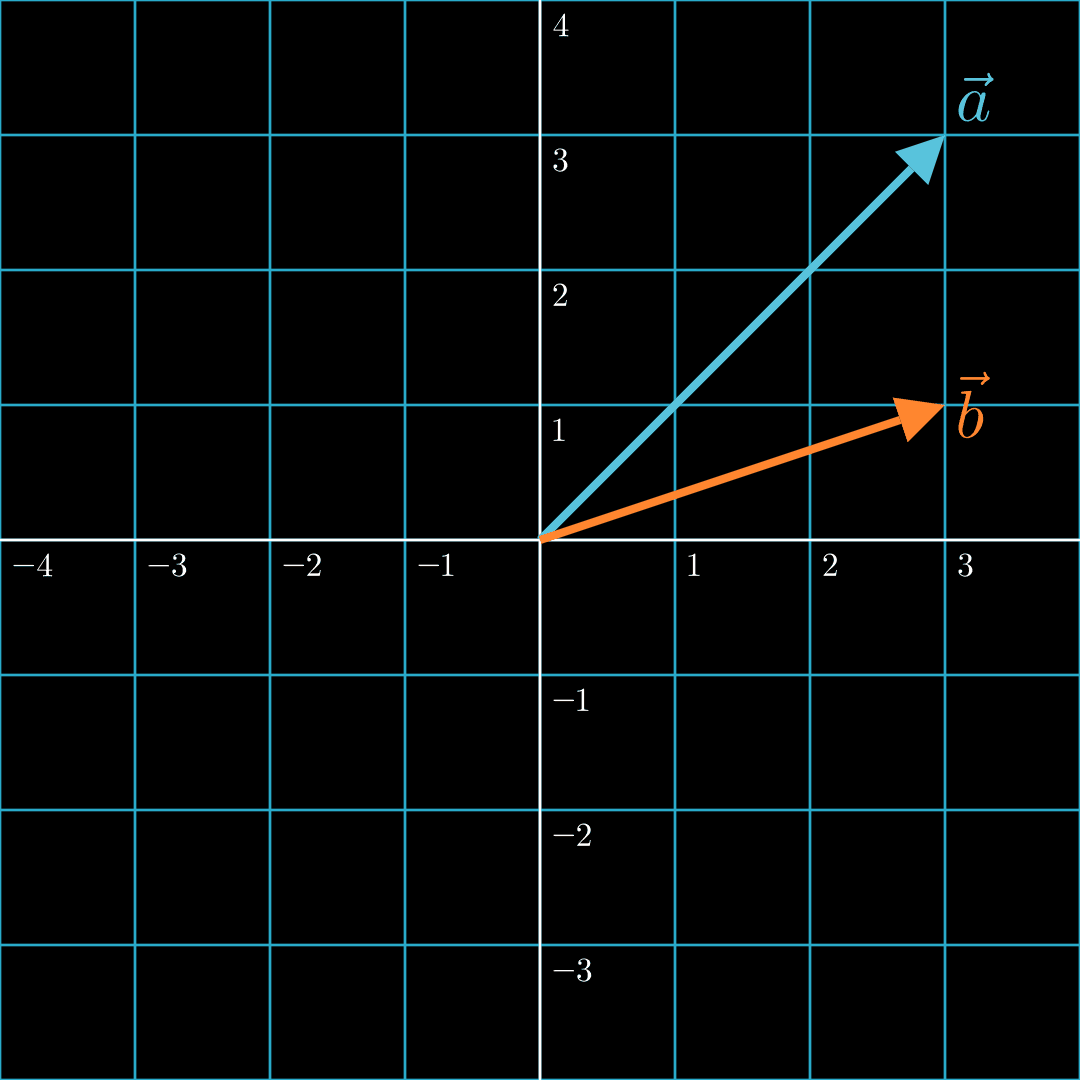
In this case, the two vectors are generally aligned and pointing in the same general direction. Formally, the angle between the two vectors is less than 90°. Hence, a positive dot product.
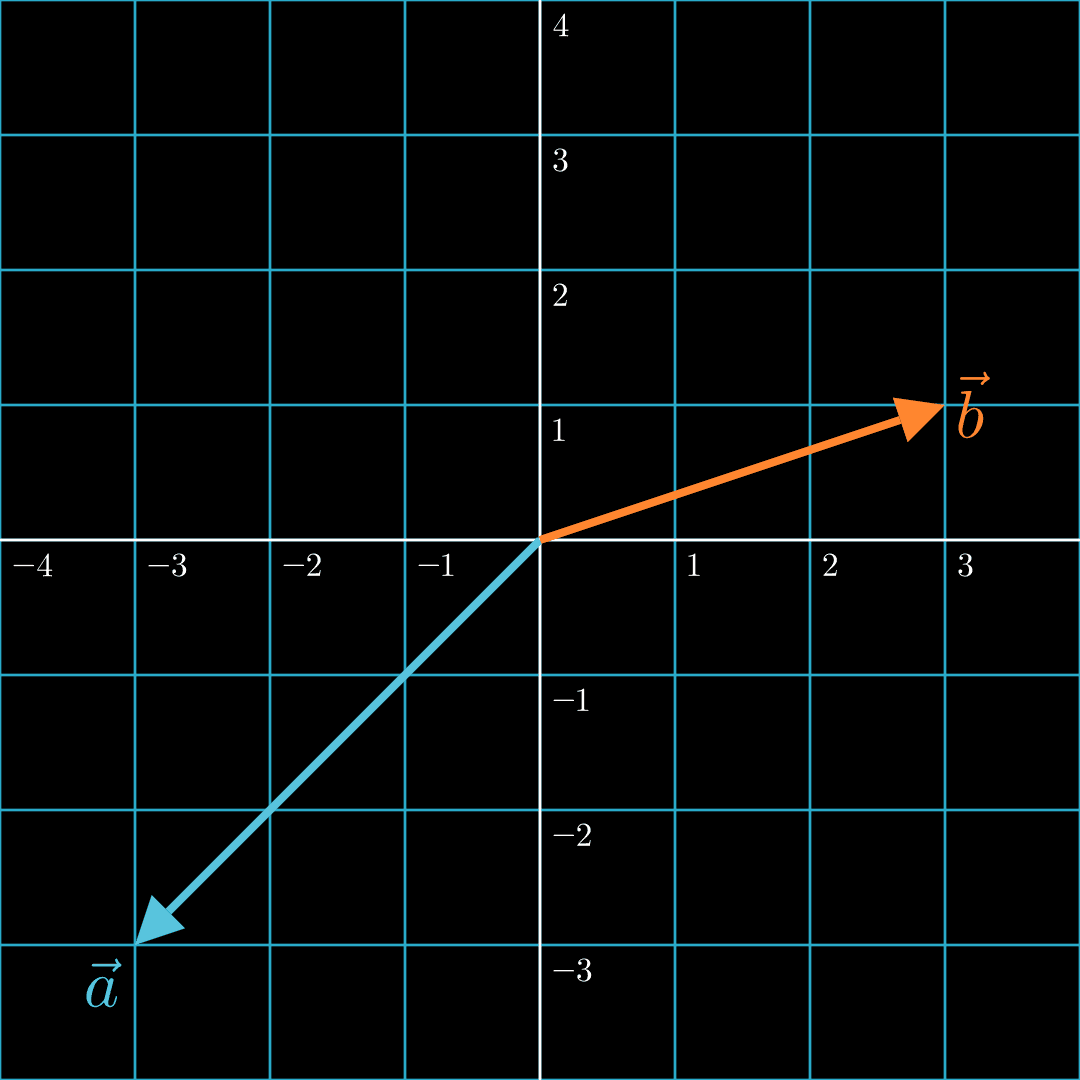
In this case, the two vectors are generally not aligned and pointing in roughly opposite directions. Formally, the angle between the two vectors is greater than 90° and less than 270°. Hence, a negative dot product.
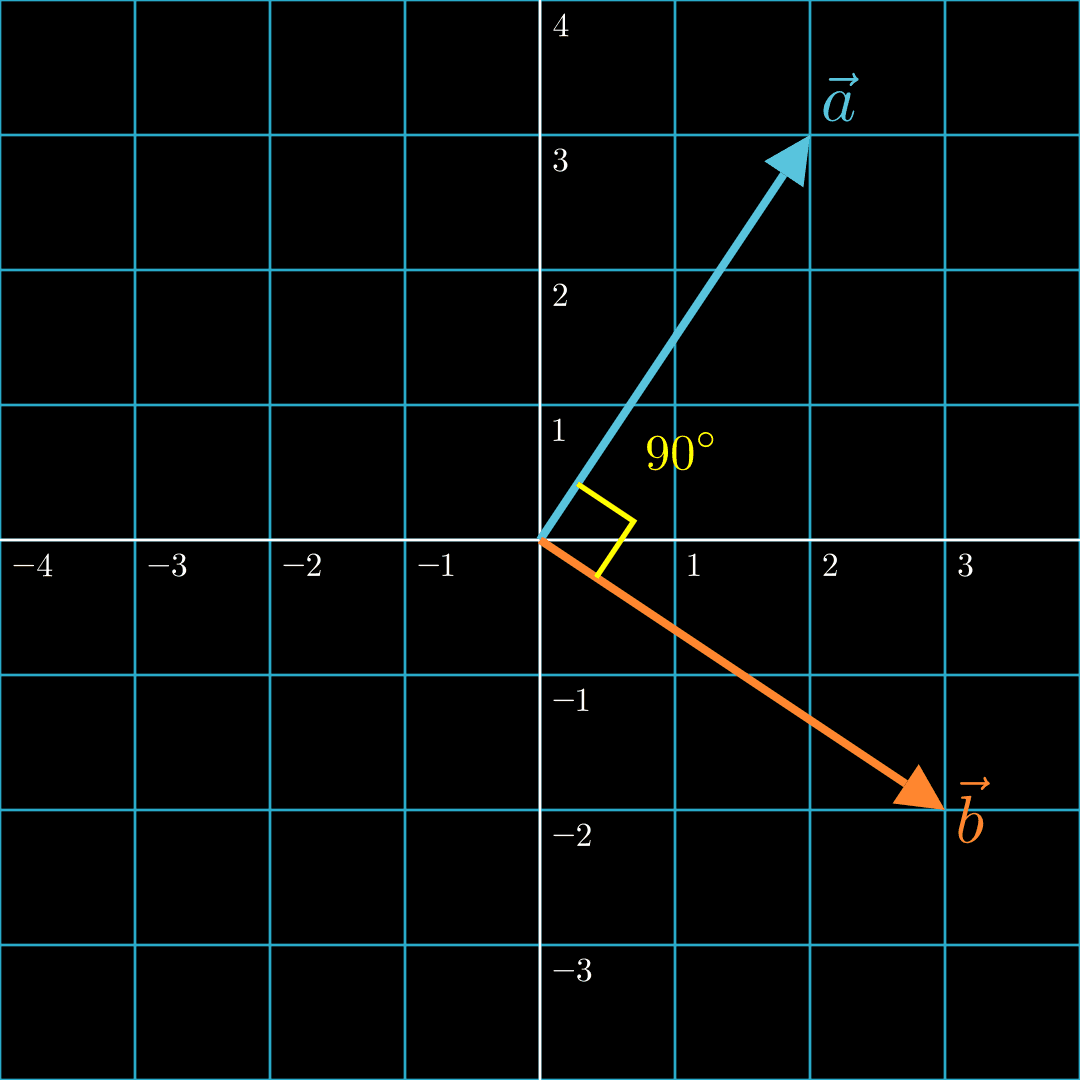
In this case, the two vectors are perpendicular. They are neither aligned nor misaligned. Thus, the dot product is zero.
Don't worry if you're still trying to grasp these concepts. We just covered a lot of math. You can go back to the Interactive Dot Product Playground above to build intuition around the relationship between the dot product and the lengths and direction of vectors.
Embeddings
How does any of this math apply to machine learning? It turns out our new knowledge of vectors and dot products can be applied to large language models like ChatGPT, image generation like DALLE, and movie recommendation systems like Netflix.
As we will learn in a future article, AI applications based on neural networks do not process images, text, video, and audio directly. Instead, these inputs are first converted to vectors and matrices, and then these vectors and matrices are passed into the neural networks, which can perform various mathematical operations on them before producing output such as a chatbot response, a synthetically generated image, or a recommended movie. Even though to human eyes these vectors and matrices might seem like random but organized lists of numbers, to the neural network, they contain concepts. Vectors that represent these concepts are called embeddings. Because the seemingly random numbers in the vectors are capable of representing anything from a bird to electric cars to globalization, we say that these embeddings capture semantic meaning.
To illustrate, let's take a look at three popular movies. Suppose The Avengers: Endgame is represented by a vector that spans from the origin to , Spiderman by a vector that points to , and La La Land by a vector that points to . Alternatively but subtly, we can view these movies as just the points at the end of the vector as opposed to the entire vector (e.g., Spiderman is just as opposed to the vector pointing to ). These are equivalent representations.
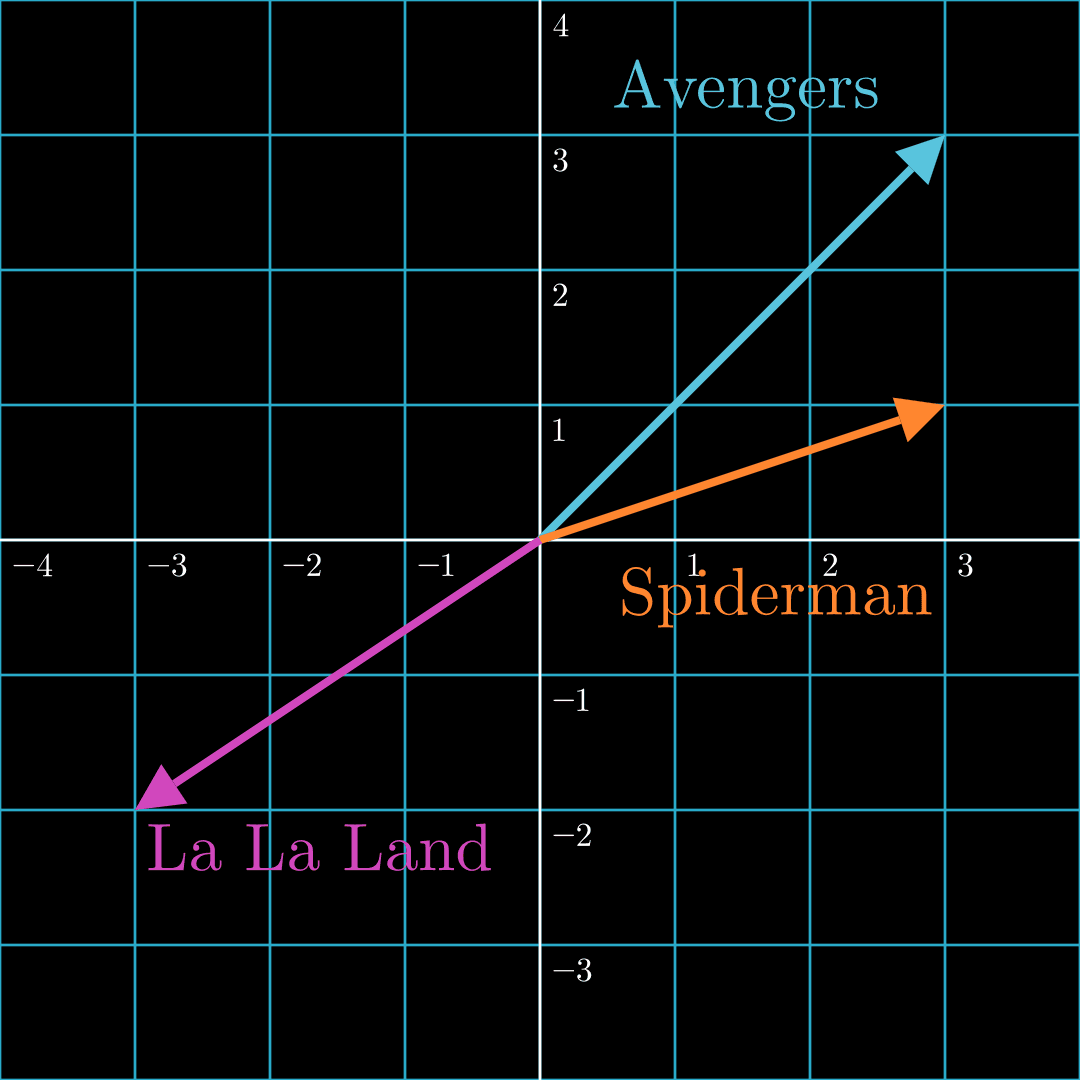
Since The Avengers: Endgame and Spiderman are Marvel superhero movies, their vectors would be roughly aligned and thus their dot product would be positive. However, the movie La La Land has less action and a more serious overtone. Thus its dot product with the other two movies would be negative.
We will cover how to produce these coordinates for the movies in Part 3 of this series, but for now, assume these are the points/vectors representing their movies. These vectors are meaningless to us if we just randomly choose values for the vectors, but if they are chosen in such a way that the vectors for The Avengers: Endgame and Spiderman point to coordinates that are closer together than they are to the coordinate for La La Land, the vectors could be useful. What operation would tell us the degree to which two points are close together or the degree to which two vectors are aligned? The dot product.
This is a useful concept in machine learning because we can convert almost anything into an embedding if we have a properly trained neural network model. This concept of using the dot product to gauge the similarity between concepts, ideas, and objects will be the basis of the image search engine we'll build in Part 3.
Embeddings from OpenAI's CLIP Model
The diagram above with the three movies contained a toy example. Let's use a properly trained neural network to produce embeddings from words of five different categories. Suppose we have words from the following categories:
- 🌹 flowers
- 🧪 elements of the periodic table
- 🎸 music genres
- ⚽️ sports
- 🗼 European cities
Intuitively, if we had vectors that represented words from these different categories, ideally the vectors representing words from the same category would point to coordinates that are clustered together. Let's explore this idea. Below is an interactive playground (viewable on laptop/desktop only) that allows you to examine the embeddings of various words from these categories. The embeddings were produced by passing the words into a neural network from OpenAI called CLIP. We'll discuss more about CLIP in Part 3 of this series, but in essence, this model is able to accept either text or images as input and produce embeddings as output. Hover over each word to see their 2D coordinates. Determine if the words that are visually close together belong to the same category.
We passed in five different categories of words to CLIP, and as expected, five distinct clusters appeared among the embeddings. Notice that the genres of music are clustered together in the center, the types of flowers are together on the left, the sports are in the upper right-hand corner, the European cities are in the bottom right-hand corner, and the elements of the periodic table are on the bottom left. One exception is the word pop. While pop is a genre of music, it is also an overloaded term that has multiple meanings, which is probably why it's not clearly clustered together with the other music genres.
Conclusion
Congratulations! We just made significant progress toward building cool and exciting ML applications in the next part of this series. We learned the algorithm to calculate the dot product, and then we gained visual intuition around this operation. Then we learned about a special type of vector called embeddings, and we explored the embeddings generated by a neural network called CLIP. In Part 3, we will tie all of this knowledge together to build an image search engine.
Quiz